# LinkedList源码分析
# 📝 LinkedList源码分析
虽然一般都是使用ArrayList集合比使用LinkedList集合要多,但是这并不妨碍我们对LinkedList的源码研究和学习
# 数据结构和参数
LinkedList 是一个双向链表的结构,这点可以直接看其内部内就可以非常明显的看出来. 静态私有的内部类,只提供一个构造函数
头节点的上一个指针是Null;尾节点的下一个指针是Null
如果头节点和尾节点都是null的话,则说明该LinkedList只有一个元素
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
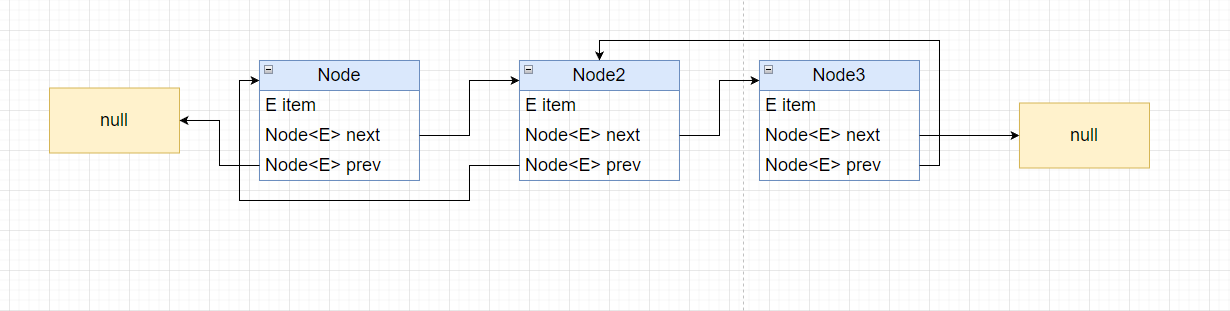
然后我们看 LinkedList 自身的变量. size 肯定是记录这个链表的长度,不然到时候node.next.next....获取长度就很得不偿失了. 然后记录了一个头节点和尾节点,个人认为这是方便遍历。从头开始遍历就从first节点获取,从尾部开始遍历的话,就从last开始获取
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
* 记录头节点
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
* 记录尾节点
*/
transient Node<E> last;
# 方法
# add(E e)方法
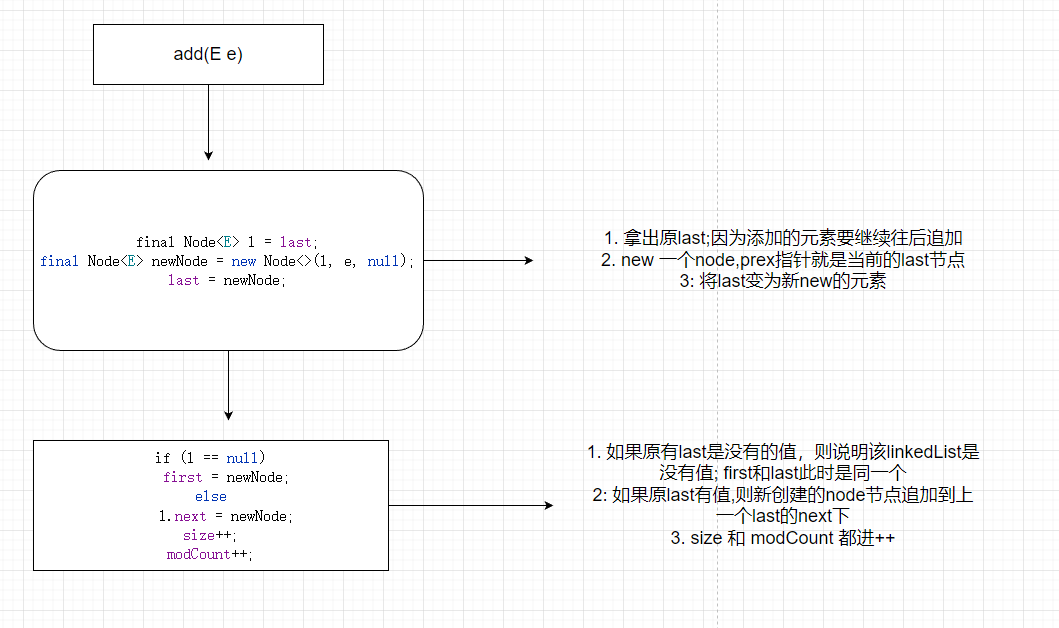
add方法调用一个linkLast方法,然后就返回true了. 也就是说add(E e)就是默认从尾部开始插入元素进去
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
翻译 : 链接e作为最后一个元素。
先对last赋值给 Node<E> l , 然后调用new Node<>(l,e,null);传入进去的上个节点,也就是l,上次保存的尾部节点,也就是从倒数第一变为了倒数二,这样理解。然后此时的newNode就是尾节点了,然后赋值给last,因为last每次记录的都是尾节点.
if else 中是对之前的尾节点进行判断,如果是null的话,说明此时就是添加的第一个元素,first也赋值给newNode,否则的话,l.next 和 尾节点进行关联。
size 长度加一
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
方法解析流程如下
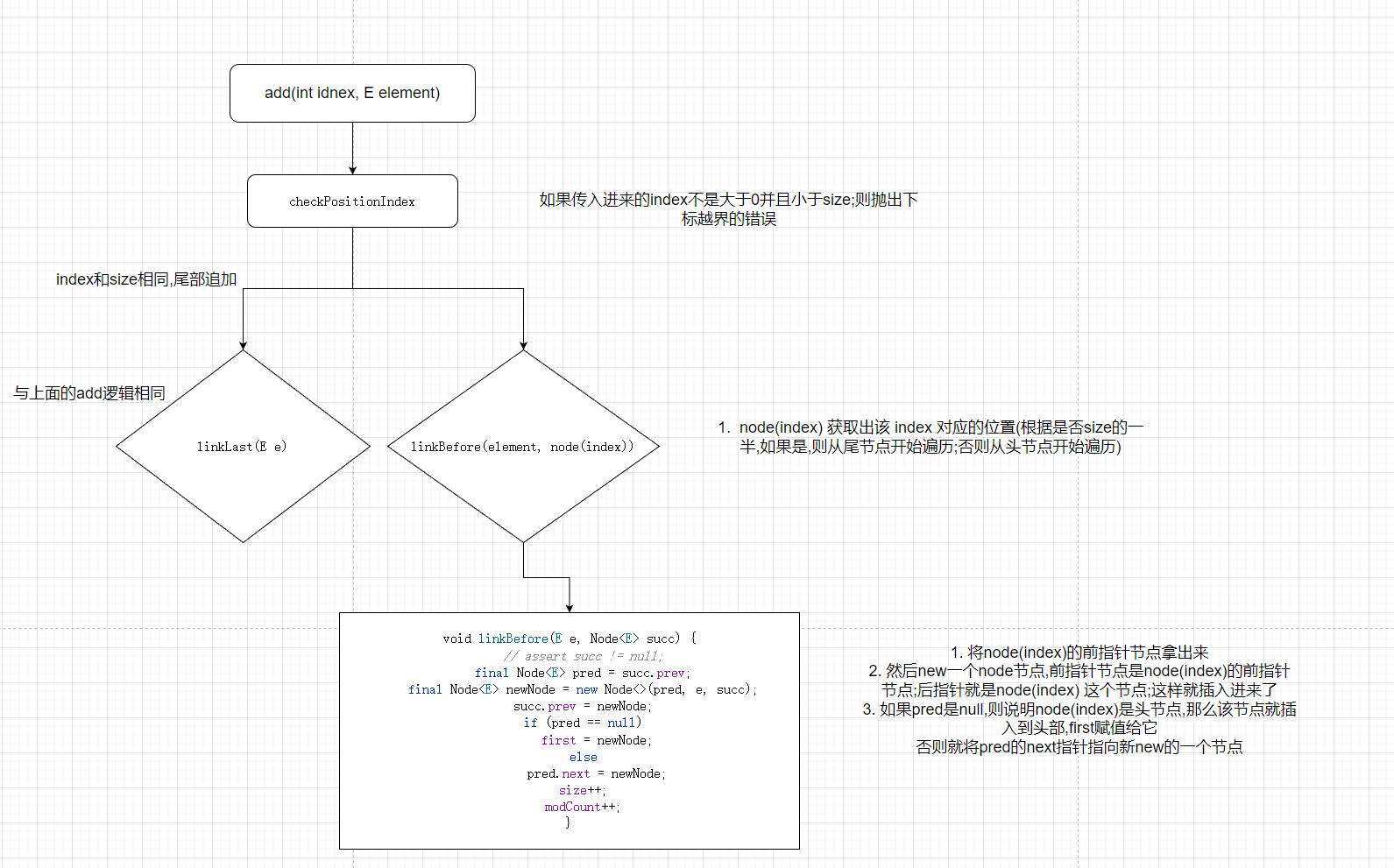
# add(int index,E element)根据下标添加
/**
1: 检查传入进来的下标是否越界了,如果下标越界的话,就会抛出 下标越界的异常
2: 根据传入进来的下标值,判断是否和 size 相等,如果是相等的话,就说明是尾部插入,就不需要挨个迭代去获取对应的下标值对应的节点.满足条件,就会调用上面说到的 linkLast方法
3: 不满足条件2的话,就会走lineBefore()方法,其中也调用到了.传入下标调用node方法.node会返回对应下标的值,根据返回的节点和当前的值调用lienkBefore方法.
*/
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
/**
size >> 1 ; 是对 size 进行去半, 比如 6 >> 1 是 3, 5 >> 1 是2
如果小于一半的话,就会从first节点开始遍历,也就是从头节点开始遍历,否则就是从尾节点开始遍历.
这个方法可以看到,从头开始遍历的话,就是调用的next,如果尾部遍历的话,调用的就是prev。找到对应下标的节点并且返回回去.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/**
获取节点的上个节点赋值给pred,其实类似于pred这种,都是用于变量替换创建出来的.
上一个节点,当前值e,succ节点来new一个新的节点出来.
succ.prev 指向当前new出来的节点
对pred判断是否是null,如果是null的话,就说明是第一个值,否则就是赋值上pred个节点的next
,size ++ 就是对长度 ++
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
代码逻辑如下图:
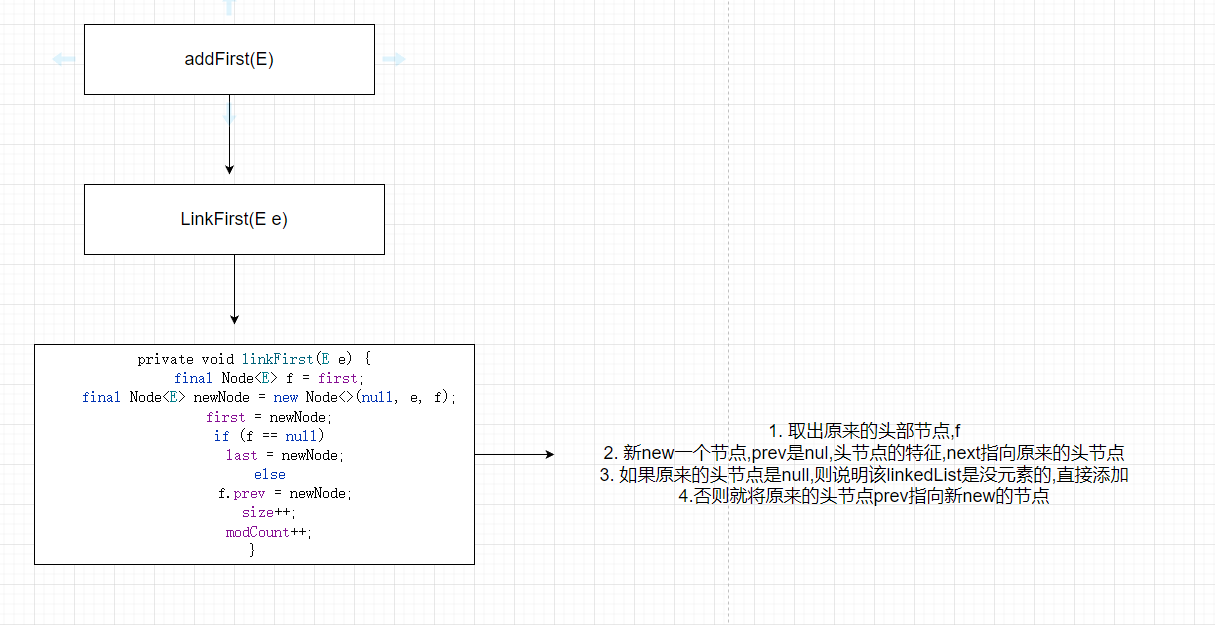
# addFirst(E e)头插入
将值插入到头部
public void addFirst(E e) {
linkFirst(e);
}
/**
先将first 赋值给 f , 根据传入进来的值e 和 下一个节点f(前一个头节点),new一个新的newNode节点出来,first指向newNode.如果f是null的话就说明是初始化,如果不是null的话,f的上一个节点指向newNode,刚刚程序newNode出来的.就完成了头节点的插入
*/
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
代码逻辑如下
# addLast(E)尾插入
与头节点相似,也是利用变量last来实现尾部插入
可参考上面的头插入图,也就是将头的判断和指针的指向倒过来,换成尾就是的了
public void addLast(E e) {
linkLast(e);
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
// 如果尾节点没有,则说明原的linkedList是没有元素的
if (l == null)
first = newNode;
else
// 原来的last的next指向新new出来的node
l.next = newNode;
// 长度和迭代的标记都+1
size++;
modCount++;
}
# get方法
根据下标来获取出值 ,然后调用node方法获取出节点,node.item就是我们需要的值,然后对其进行返回即可
参考下标添加中的图,有个node(index)的方法,get也是走的node(index)去获取的node节点;再次之前,也会进行一次index是否越界的判断
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 如果输入index是小于0和大于size的话,就会爆出下标越界的错误.
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
# getFirst / getLast方法
可以看到first和 last都是直接从定义的变量中获取出对应的值;分别从头节点和尾节点的值获取
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
# peek方法
使用first节点,如果是null的话就会返回null,否则就是f.item. 这里是没有删除first元素,poll是弹出元素并且删除
与 getFirst 逻辑一致,只是这里如果first是null的话就返回null,而getFirst是null的话,则会抛出异常
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
# peekFirst和peekLast方法
peekFirst: 获取头节点元素;其实和peek逻辑是一致的
peekLast: 获取尾节点元素;从变量last获取,如果是null返回null;否则返回对应的值
# poll方法
弹出第一个元素,并且将都一个元素的下个元素重置未第一个元素;如果next是null的话,则first也是null,说明当前linkedlist无元素了
这里主要看unlinkFirst方法
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
/**
取出 f 的item,节点对应的值和 f的next个节点,如果下个节点是null的话,就说明是没有值的,如果不为null的话,说将next的上一个节点prev指向null,因为头节点的prev和尾节点的next都是null来进行区分。
*/
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
# remove()方法
移出第一个元素,也就是和 poll 的逻辑是一致的
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
# remove(int index)方法
根据下标进来remove方法, node(index) 也是在上面进行讲到的,就是根据下标获取对应的node节点信息
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
/**
这里获取出节点的 next 和 prev方法.
该节点的上一个节点(prev)的next需要指向指向该节点的下个节点(next),该节点的下一个节点和prev的操作是相反的,因为这样的话,就删除了该节点,并且上一个节点和下一个节点关联起来了.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
# remove(Object o)
根据值来进行删除.这个可以看出来,如果有二个相同节点的值,调用一次这个方法是只可以删除一个,而不是二个
假设node节点1有二个,则你需要调用二次删除
当然你可以分别调用removeFirstOccurrence(Object o)和removeLastOccurrence(Object o)分别优先删除头和优先删除尾
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
# 🤗 总结归纳
好啦,今天的知识内容就更新到这里,虽然文字描述到很难理解,但是主要去理解 Node 节点的 双向指向,并且每次添加节点和删除添加,都是靠Node的prev和next来进行指向. 所以说LinkedList是删除快,查询慢的原因