# InnoDB
# 表空间
后面写
# 页
每个空间都被划分为许多个页,通常每个页的大小为 16KB(这个页大小可能因为两方面影响而有所变化:编译时修改了 UNIV_PAGE_SIZE 定义的值,或者使用了 InnoDB 压缩)。InnoDB 为空间中的每个页都分配了一个32位的整数页码,通常称为“偏移量”,这实际上只是这个页从空间开始位置 的偏移量(因为对于多个文件组成的空间来说,并不一定是从文件开始位置的偏移量)。因此,0 号页 位于偏移量为 0 的位置,1 号页位于偏移量为 16384 的位置,等等。(有的读者可能知道 InnoDB 有一个数据大小限制是64TB,这实际上是每个空间的大小限制,主要是由于页号是一个32位的整数,结合默认的页面大小16KB可以得到:232 x 16 KB = 64 TB)
一个页的基本布局


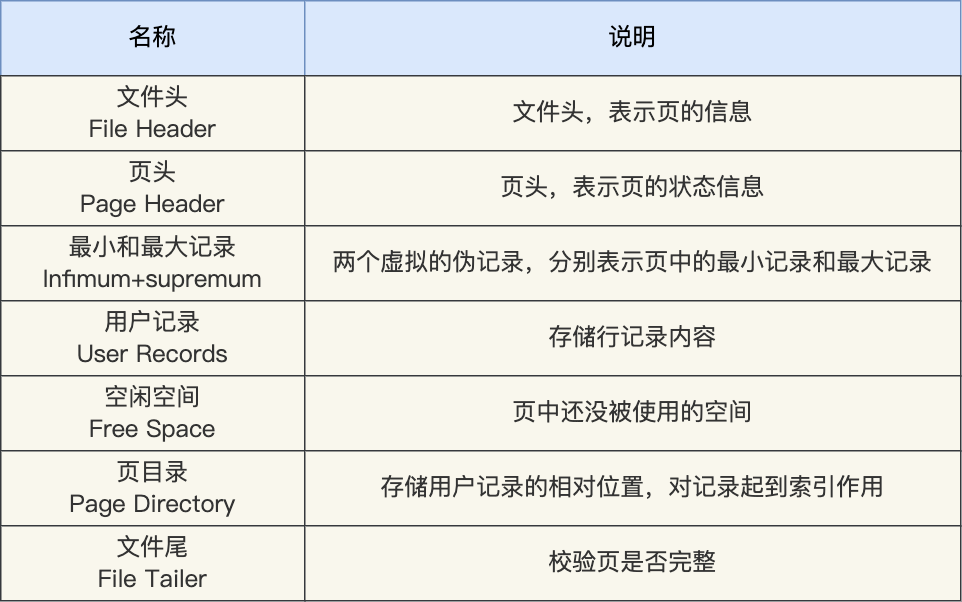
- Page Type(2):页面类型存储在 FIL Header 中。因为页被用于 文件空间管理、区段管理、事务系统、数据字典、回滚日志[undo log]、 二进制大对象[blobs],还有索引(也就是表的数据)等多种用途,不同的用途的页面可能结构不同,所以为了解析页面数据,必须要有页面类型这个字段。
- Space ID(4):当前页面所属空间的空间ID。
- Offset(Page Number)(4):页码。当页被初始化后,页码就会存储在FIL Header中。通过比较 “从该字段读取的页码” 与 “基于文件偏移量的页码” 是否匹配,可以检验页面读取是否正确,并且这个字段被初始化同时就表明页面已经被初始化。
- Previous Page(4) & Next Page(4):相同类型页面的逻辑上一页和下一页的指针存储在FIL Header中。这两个指针是用来构建双向链表的,用于将同一层级的INDEX类型页面连接起来,这在进行范围扫描的时候是非常有效的,例如全索引扫描。但许多类型的页面其实都不使用这两个字段。
- LSN for last page modification(8) & Low 32 bits of LSN(4):页面最后一次修改的日志序列号(简写为LSN,64位整数)存储在FIL Header中,并且同一 LSN 的低32位存储在FIL Trailer中。
# 索引页
索引页的结构
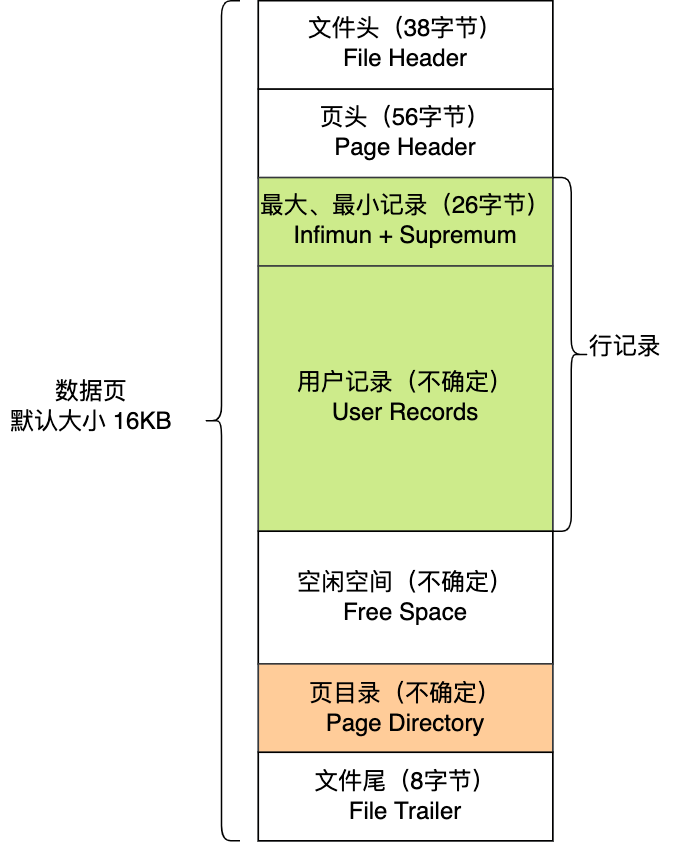
各个部分的作用
在 File Header 中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表,如下图所示:
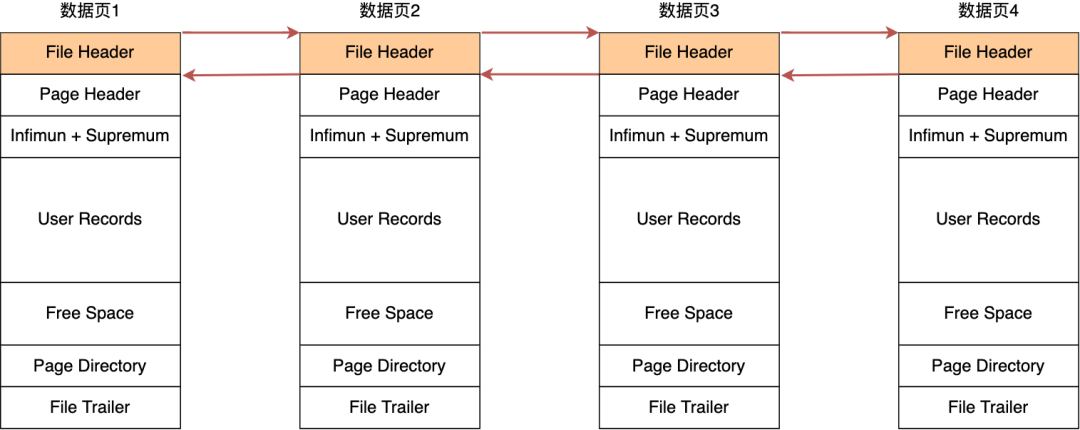
采用链表的结构是让数据页之间不需要是物理上的连续的,而是逻辑上的连续。
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
# Buffer Pool缓冲池
InnoDB 存储引擎基于磁盘存储的,并将其中的记录按照页的方式进行管理,但是由于 CPU 速度和磁盘速度之间的鸿沟,基于磁盘的数据库系统通常使用缓冲池记录来提高数据库的整体性能。
在数据库进行读取操作,将从磁盘中读到的 page (页)放在缓冲池中,下次再读取相同的页中时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中,直接读取该页,否则读取磁盘上的页。
对于数据库中页的修改操作,首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上,页从缓冲池刷新回磁盘的操作并不是在每次页发生更新时触发,而是通过一种称为 CheckPoint 的机制刷新回磁盘。所以,缓冲池的大小直接影响着数据库的整体性能,MySQL 官方文档给出的建议是物理机器的 50%-75% 的占比 (opens new window)
由于缓冲池不是无限大的,随着不停的把磁盘上的数据页加载到缓冲池中,缓冲池总要被用完,这个时候只能淘汰掉一些缓存页,淘汰方式就使用 LRU(最近最少被使用)算法,具体来说就是引入一个新的 LRU 链表,通过这个 LRU 链表,就可以知道哪些缓存页是最近最少被使用的,那么当你缓存页需要腾出来一个刷入磁盘的时候,可以选择那个 LRU 链表中最近最少被使用的缓存页淘汰。
# 参考链接
← mpp型数据库